算法定义
对特定问题求解步骤的一种描述。
算法特征
- 有穷性:算法必须总是执行有穷步之后结束且每一步都在有穷时间内完成
- 确定性:每一条指令必须有确切的含义
- 可行性:算法是可行的
- 输入:有零个或多个输入
- 输出:有一个或多个输出
算法效率的度量
算法执行时间需通过依据该算法编制的程序在计算机上运行时所消耗的时间来度量。
时间复杂度
算法执行时间的变化趋势可以表示为输入规模的一个函数,称作该算法的时间复杂度,记作$T(n)$。从保守估计的角度出发,$T(n)$就是所有输入中执行时间最长的。
渐进复杂度
为什么要引出渐进复杂度?是因为在评价算法运行效率的时候,我们往往是可以忽略其处理小规模问题时的能力差异,转而去关注其在处理更大规模问题时的表现。因为小规模问题处理起来时间本来就少,故此时不同算法的实际效率差异并不明显;而在处理更大规模的问题的时候,效率的些许差异都将对实际执行效果产生巨大的影响。
所谓的的渐进分析就是着眼长远、更为注重时间复杂度的总体变化趋势和增长速度的策略和方法。
为了更好的度量和评价时间复杂度的渐进增长速度,引入三个符号:$O,\Omega,\Theta$来分别渐进分析一个算法的最好、最坏和平均情况。
大$O$记号
首先这是一个函数,函数就可以输入进去变量,然后输出经过函数处理过后的值,先给出下面的公式,然后再做推导。
推导:具体地,若存在正的常数c和函数f(n),使得对任何$n>>2$(n远大于2)都有
则可认为在n足够大之后,f(n)给出了T(n)增长速度的一个渐进上界,也就是公式(1)。上面式子中的f(n)函数指的是算法中基本操作重复执行的次数是问题规模n的某个函数,也就是说f(n)代表了这个算法中所有语句执行次数的和。
通俗的理解上面的两个式子,就得先知道O到底干了什么,首先它是一个函数,前面说了函数的话是会在里面执行一些操作,而O进行的操作就是把输入里面的变量做了这两种变化:1、所有的正的常数项系数可以忽略并等同于一;2、多项式中只保留最高次项。那就好理解公式(1)中为什么用等于号了,因为经过这两步变换后,输入O的变量自然会小于等于$c\cdot f(n)$,都小于等于的话就可认为$T(n)=O(f(n))$了。根据上面的定义,就可以得出大$O$的如下两个性质了
可以看出,大$O$记号的这些性质很好地体现了对函数总体渐进增长趋势的关注和刻画。
一个例子,在冒泡排序算法中,最差的输入情况需要执行的基本操作不会超过$2(n-1)^2$次,表示为该算法的时间复杂度为
根据大$O$记号的性质,就可以进一步简化和整理为
大$\Omega$记号
为了对算法的复杂度最好情况做出估计,需要借助另一个记号。如果存在正的常数c和函数 g(n),使得对于任何n >> 2都有
就可以认为,在n足够大之后,g(n)给出了T(n)的一个渐进下界。此时,我们记之为
与大O记号恰好相反,大$\Omega$记号是对算法执行效率的乐观估计——对于规模为n的任意输入,算法的运行时间都不低于$\Omega$(g(n))。比如, 即便在最好情况下,起泡排序也至少需要T(n) = $\Omega$(n)的计算时间。
大$\Theta$记号
借助大O记号、大$\Omega$记号,可以对算法的时间复杂度作出定量的界定,亦即,从渐进的趋势看,T(n)介于$\Omega$(g(n))与O(f(n))之间。若恰巧出现g(n) = f(n)的情况,则可以使用另一记号来表示。
如果存在正的常数c1 < c2和函数h(n),使得对于任何n >> 2都有
就可以认为在n足够大之后,h(n)给出了T(n)的一个确界。此时,我们记之为:
它是对算法复杂度的准确估计——对于规模为n的任何输入,算法的运行时间T(n)都与$\Theta$(h(n))同阶。
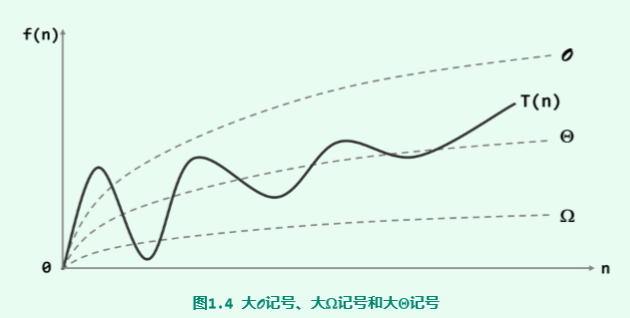
常用算法复杂度
由于算法的时间复杂度考虑的只是对于问题规模n的增长率,则在难以精确计算基本操作执行次数(或语句频度)的情况下,只需求出它关于n的增长率或阶即可。以下学习记录了几种常见数量级的时间复杂度。
常数O(1)
一般地,仅含一次或常数次基本操作的算法。此类算法 通常不含循环、分支、子程序调用等,但也不能仅凭语法结构的表面形式一概而论。
对数O(logn)
该复杂度最城建的就是二分法查找,每次数据规模n都会减半,学过高中数学可以知道,对数是用来求次数的,这应该有个2,在界定渐进复杂度的时候具体取值无所谓,这里logn可以看做是执行的次数,即减半了多少次。
线性O(n)
该复杂度即线性时间复杂度,可以认为在一个for循环内完成的时间复杂度。
多项式O(polynomial(n))
若运行时间可以表示和度量为T(n) = O(f(n))的形式,而且f(x)为多项式,则对应的算法 称作“多项式时间复杂度算法”。
指数O($2^n$)
当问题规模较大后,指数复杂度算法 的实际效率将急剧下降,计算时间之长很快就会达到令人难以忍受的地步。
复杂度层次
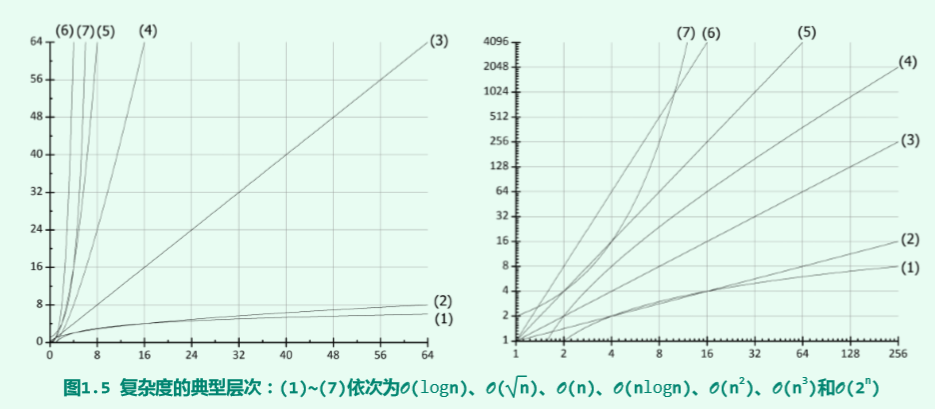
算法复杂度分析方法
观察循环层数
三重循环
看下面的矩阵乘法代码,可以看到一共有三个for循环,那么里面的那条语句的执行次数也就是$n^3$。如果n的取值为200时,大约就是要执行$8\times10^6$次基本操作。比赛中一般执行次数在$10^7$内为最佳。
1 | void matrix_Mul(){ |
带有隐性循环的strlen
下面的代码中,很容易看成只有一个for循环,然后判定时间复杂度为O(n),其实不然,因为strlen(ch)函数实际上需要走遍字符串中的每个字符。所以其复杂度实际上应该为O(n^2)。所以在以后使用strlen的时候,最好是将其放在循环外面。
1 | void cout_A(){ |
确定搜索状态数
$n^n$的排列
相比于循环,搜索的时间复杂度并不那么直观;但是只要将每个状态作为一个单位来分析,再乘以每个单位对应的时间复杂度,对应的时间复杂度分析也就不难了。简单地说,搜索的时间复杂度=每个状态对应的时间复杂度x状态数(如果不一样时,视情况分类处理或按最坏情况计算)。只要理解了这段话中的状态基本上就懂了为啥下面的这个代码的复杂度是O($nn^n$)。这个状态也就是指的可能的结果有多少中,在下面这个题目中也就是res数组有多少种情况,从depth=1开始,也就是说数组的每一位都可能是从1~n,所以就有$n^n$个可能的状态(这个和高中的排列差不多),*但是前面要乘以n就比较难理解了,这个意思就是指的每一个状态的时间复杂度,可以这么想,我定下了一个状态是数组的值全部为1,那么就要循环遍历执行复杂度为n的赋值操作啊!
1 | void dfs(int depth){ |
不能有重复的排列
在上面的分析基础上添加限制条件,不允许数组中的状态有重复的数字,那么就可以想象成全排列了也就是n!。于是代码可以写成下面的,而复杂度也就变成了O(n*n!)。
1 | void dfs(int depth){ |
变全排列为组合,进一步降低时间复杂度
如果再添加限制条件,使选择顺序和答案无关,时间上就变成了一个组合问题,也就是前面已经出现过的状态,后面就不要再出现了。深搜中剪枝优化的本质就是通过减少不必要的状态数来减少程序的运行时间,而记忆化搜索则通过减少重复计算的等价状态数来减少程序的运行时间。受限于极高的时间复杂度,每个状态对应消耗的时间往往原本就很短,通常不具备优化潜力。看下面的代码,也就是说前面已经填了的数,后面就不要再填了,这样就能保证只有一种状态了。
1 | void dfs(int depth,int last){ |
动态规划和记忆化搜索之所以快于深搜的本质就在于它们极大地减少了需要计算的状态数,避免了大量的重复计算。动态规划的一大要求,就是状态的无后效性——这就意味着对之后的状态来说,之前的所有导致这个状态发生的路径都是等价的。
一个分析递归时间复杂度的例子
下面是一个分析递归时间复杂度的例子,这个例子其实也不难理解,首先要看有多少个状态数,或者可以想象成每层递归会产生多少个中间结果,然后每个状态的时间复杂度也就只有一行代码,所以每个状态的时间复杂度好确定,也就是O(2),然后就要确定状态数,不好想的话也可以直接思考那行代码执行了多少次啊。首先看他每个状态都会产生两个后继,递归d层的话也就是$2^d$成指数增长,然后看到了x/2,每次数据规模都会除以2,那么递归的次数就好确定了,就是O(logn)层了,所以总的时间复杂度就是O($2^{logn}$),也就是O(n)。
均摊时间复杂度
均摊时间复杂度:对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度较高。而且这些操作之间存在前后连贯的时序关系,在这个时候,我们可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度较低的操作上。(在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度)
这个其实也好理解,也就是达到某个条件之后开始进入循环,然后此时的时间复杂度突然变化很大,这个时候利用加权平均法推导一下,利用大O记号约掉常数项和系数就可以得到最后的结果,举例的话可以看参考链接中的均摊时间复杂度。
分治的时间复杂度
在遇到因状态不同而导致时间复杂度不同的情况时,需要进行分类处理,也就是每一次递归的数据的状态差异较大时。如下面的分治法的列子,对于递归过程的第i层,一共有$2^i$个状态,这里还可以套用之前的公式,一共有$\frac{n}{2^i}$个状态,
以上这些在《算法导论》中都有比较详细的讲解,等有空再好好拜读一下。